

By Adrien Payong and Shaoni Mukherjee

众多团队在扩展 large language model 工作负载时,往往会遭遇同样的棘手难题:尽管购置了性能更强的 GPU,部署了规模更大的推理集群,但延迟和吞吐量的目标依然无法达成。究其原因,其实并不复杂:LLM 推理的效能并非受限于单一硬件组件。性能表现取决于整个服务栈的全链路协同,涵盖从 Tokenization(分词)与 Prompt 预处理,一直到 KV-cache 管理、GPU 调度以及 Token 流式输出的所有环节。实际上,推理速度缓慢往往是系统性的问题。
现代服务栈(如 vLLM、Hugging Face Text Generation Inference 以及 TensorRT-LLM)正是基于此理念而设计。它们特别强调持续(飞行中)批处理、优化的 KV-cache 利用率、Paged Attention、分块 Prefill 以及调度策略等能力,旨在最大化加速器的利用率,同时不牺牲用户体验的可见延迟。之所以强调这一点,是因为 LLM 推理 实际上包含两种截然不同的性能模式:Prefill(预填充)阶段通常属于计算密集型,而 Decode(解码)阶段则往往受限于内存带宽与 KV-cache 的数据搬运,而非单纯的吞吐量。
本文将探讨在生产环境中那些常被忽视、却可能拖慢 LLM 推理速度的瓶颈,并提供相应的解决思路。
Key Takeaways
- LLM 推理本质上是系统工程问题,而非仅限于 GPU:性能优劣取决于全流程管道——从分词到 KV-cache 及调度——而非单一组件。
- Prefill 与 Decode 的行为逻辑截然不同:Prefill 侧重计算密集,而 Decode 常受内存带宽制约,需要差异化的优化策略。
- GPU 高占用并不代表高效能:系统看似繁忙,但若受限于内存瓶颈或调度不当,实际吞吐量可能依然很低。
- 批处理策略与规模直接影响用户体验:大批次虽能提升吞吐,但可能增加延迟,特别是对 TTFT(首字延迟)和 Token 间延迟不利。
- 现代化服务架构优于传统设计:连续批处理、前缀缓存以及优化的 KV-cache 管理能显著改善实际场景下的性能表现。
What Actually Happens During an LLM Inference Request
让我们深入拆解一次 LLM 推理请求的内部流程。从外部视角看,每个请求的概念逻辑似乎很简单:用户提交文本,随后接收返回的 Token。但在服务栈内部,处理管道则复杂得多:
request → tokenization → prefill → KV-cache creation or reuse → decode → GPU scheduling → streamed output
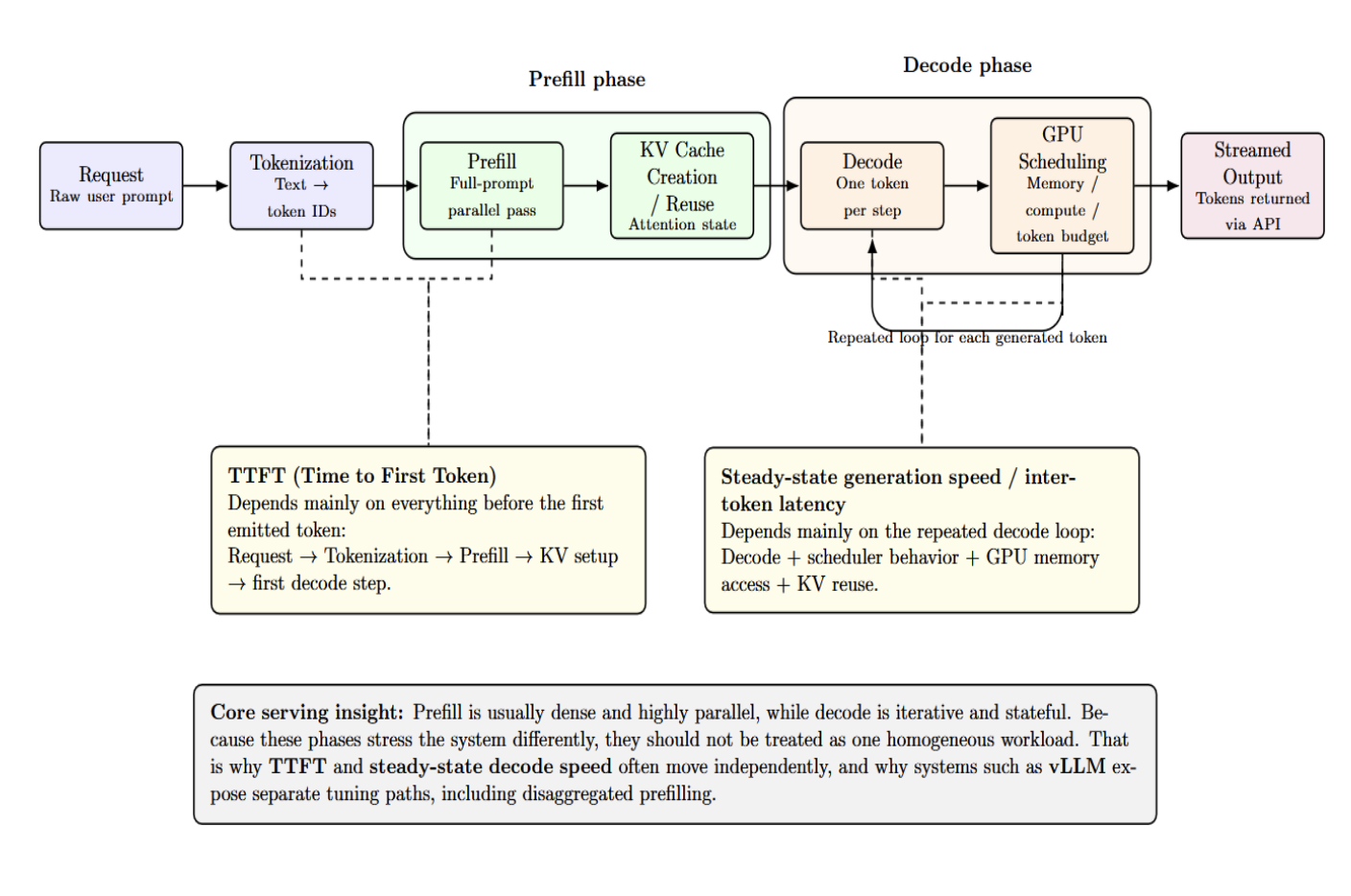
首先,请求必须经过 Tokenization,即将原始文本转换为对应 Token 的 ID。接着,Prefill 阶段会对整个 Prompt 进行并行批处理,并初始化 KV-cache。随后,Decode 阶段开始迭代运行,逐个生成 Token 并持续复用 KV 状态。系统调度器进而决定这些操作如何共享 GPU、内存及 Token 预算。
解码完成后,Tokens 通过 API 层流式传输给用户。正是由于这种机制,Prefill 和 Decode 的耗时往往会出现差异。这也解释了为什么 TTFT(首字时间)与稳态生成速度通常呈现独立的波动:前者高度依赖于首个 Token 输出前的所有前置步骤,而后者则取决于重复的 Decode 循环效率。
Prefill 与 Decode 的这种分离,是 LLM 服务设计的核心理念之一。Prefill 通常可以做到高密度并行化,而 Decode 则本质上是迭代的、有状态的。若系统将这两个阶段视为同质化工作负载来处理,就会错失性能优化的良机。这也是为什么 vLLM 的工作流极力建议对两者进行独立调优。在我们的仪表板中,TTFT 是与 Token 间延迟分开优化的。其 disaggregated prefilling 特性正是为了应对这些目标往往需要不同优化策略的情况而存在。
Hidden Bottleneck #1 — GPU Underutilization
在 LLM 运维中,最具误导性的指标之一就是仅仅看“GPU 存在”,而非实际的 GPU 效率。一个看似“繁忙”的集群,其请求吞吐量可能极其糟糕。原因何在?
因为现实世界的流量是异构的。有的 Prompt 很短,有的很长。有的输出在二十个 Token 后就结束了,有的则需数百个。在这种环境下,静态的请求级批处理显得力不从心,因为整个批次的处理速度往往受限于最慢的那个序列。当某个请求提前完成时,其对应的插槽就会闲置,直到整个批次处理完毕。
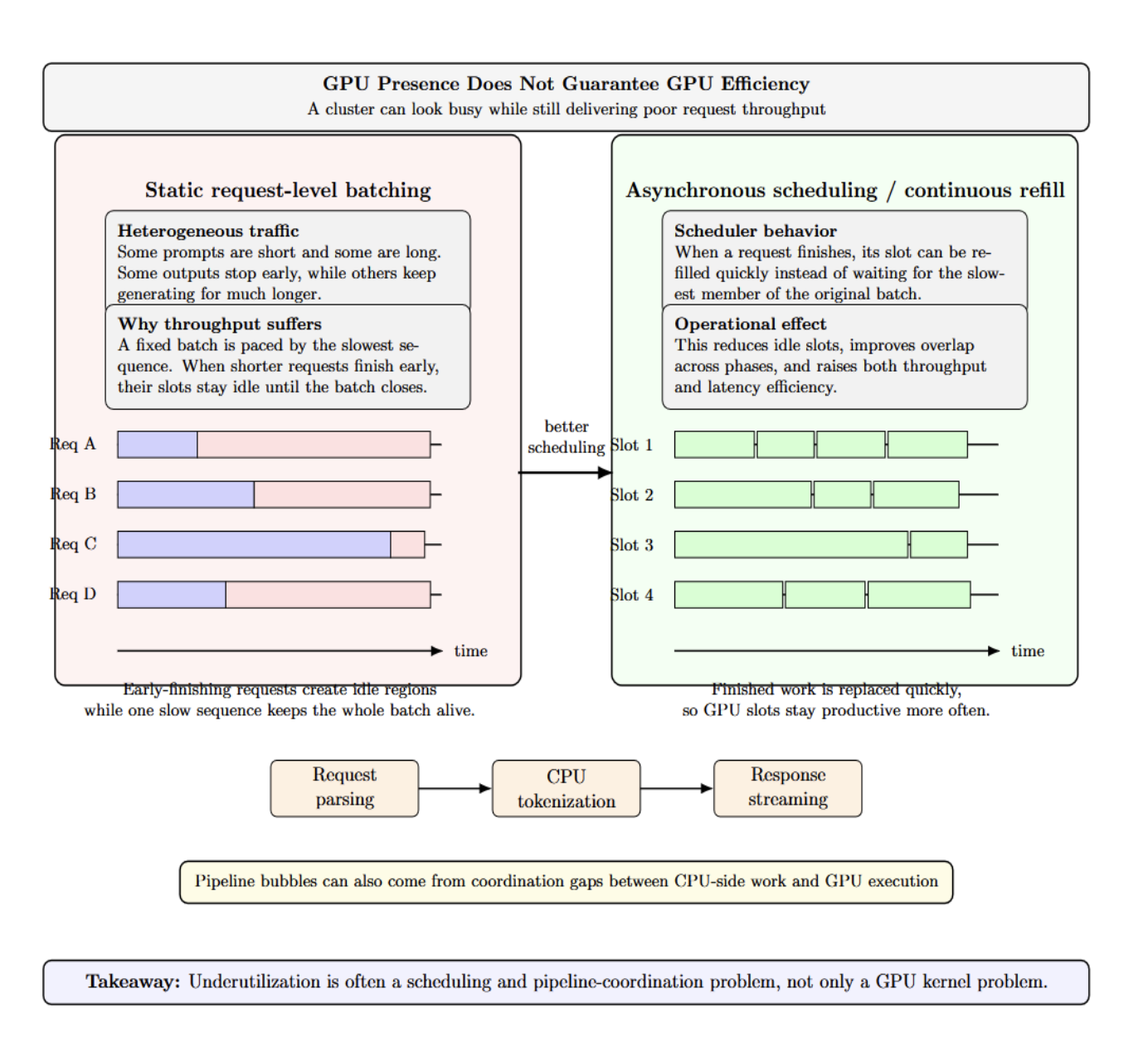
此外,阶段之间的间隙也会造成闲置。CPU 侧的预处理、分词、请求解析以及响应流式输出,都会产生让加速器等待的空隙。vLLM 的服务文档特意通过异步调度来填补这些空隙,从而兼顾延迟与吞吐。请记住:利用率低并不总是内核计算的问题,有时它仅仅是流水线协同的问题。
单纯购买更大的 GPU 无法解决调度低效的问题。如果请求长短不齐,批次僵化,或者主流程无法及时供给数据,那么性能更强劲的加速器也只能在旁边空转……而且空转得更快。
Hidden Bottleneck #2 — Memory Bandwidth, Not Raw Compute
人们常有一种思维定势,认为推理主要是一个 FLOPS(算力)问题。但实际情况是,“Decode”阶段往往在遭遇算力瓶颈之前,就会先撞上内存的墙。执行模型通常受限于内存带宽。Decode 工作线程之所以受限于内存带宽,是因为它们每次只生成一个 Token,却需要反复读取模型状态和 KV 数据。
这也就解释了为何系统明明显示内存占用很高,算术利用率却依然低下。在解码过程中,GPU 花在搬运权重和 KV-cache 数据上的时间,可能比进行繁重的张量计算还要多。这也是为什么在服务大模型时,高带宽内存(HBM)显得尤为关键。瓶颈往往在于供给下一步 Token 的数据传输速度,而非产品规格表上标称的峰值矩阵乘法速率。
这意味着在实践中,“GPU 利用率”和“GPU 效率”是不能划等号的。一个部署环境可能看起来负载已满,但每秒生成的 Token 数量却很少,因为内存流量已经成为了主要的制约因素。
Hidden Bottleneck #3 — Latency vs Throughput Tradeoffs
每个服务团队最终都会面临同样的诱惑:为了提升 吞吐量,我们或许应该增加批次大小。这确实可行!但代价可能是损害用户体验。更大的批次通常意味着更高的硬件利用率,但也往往会增加 TTFT、尾部延迟或 Token 间延迟,尤其是当 Prefill 任务挤占了活跃的 Decode 资源时。反之,减少批处理 Token 预算通常会改善 Token 间延迟,而增加预算则有助于 TTFT 和吞吐量。
这种权衡的存在意味着,服务系统的优化绝不能仅凭单一指标孤立进行。如果你关注聊天的响应速度,TTFT 就很重要;如果你关注流式输出的流畅度,Token 间延迟才是关键;而吞吐量则关乎并发能力和效率。vLLM 在其基准测试和监控文档中,公开了 TTFT、TPOT、ITL、端到端延迟、百分位数据以及 Goodput(有效吞吐量),因为没有单一数值能完整捕捉推理的质量。
最佳平衡点取决于你的具体工作负载。交互式聊天、批量摘要、Agent 管道以及离线报告生成,它们的延迟容忍度各不相同。若没有明确这些目标就进行调优,无异于盲人摸象。
Hidden Bottleneck #4 — Batching Strategy
不同的批处理策略,效果天差地别。静态批处理将请求一次性打包后处理。动态批处理 在组批上更加机会主义,但对生成时长的变化可能反应不够迅捷。连续批处理则截然不同。
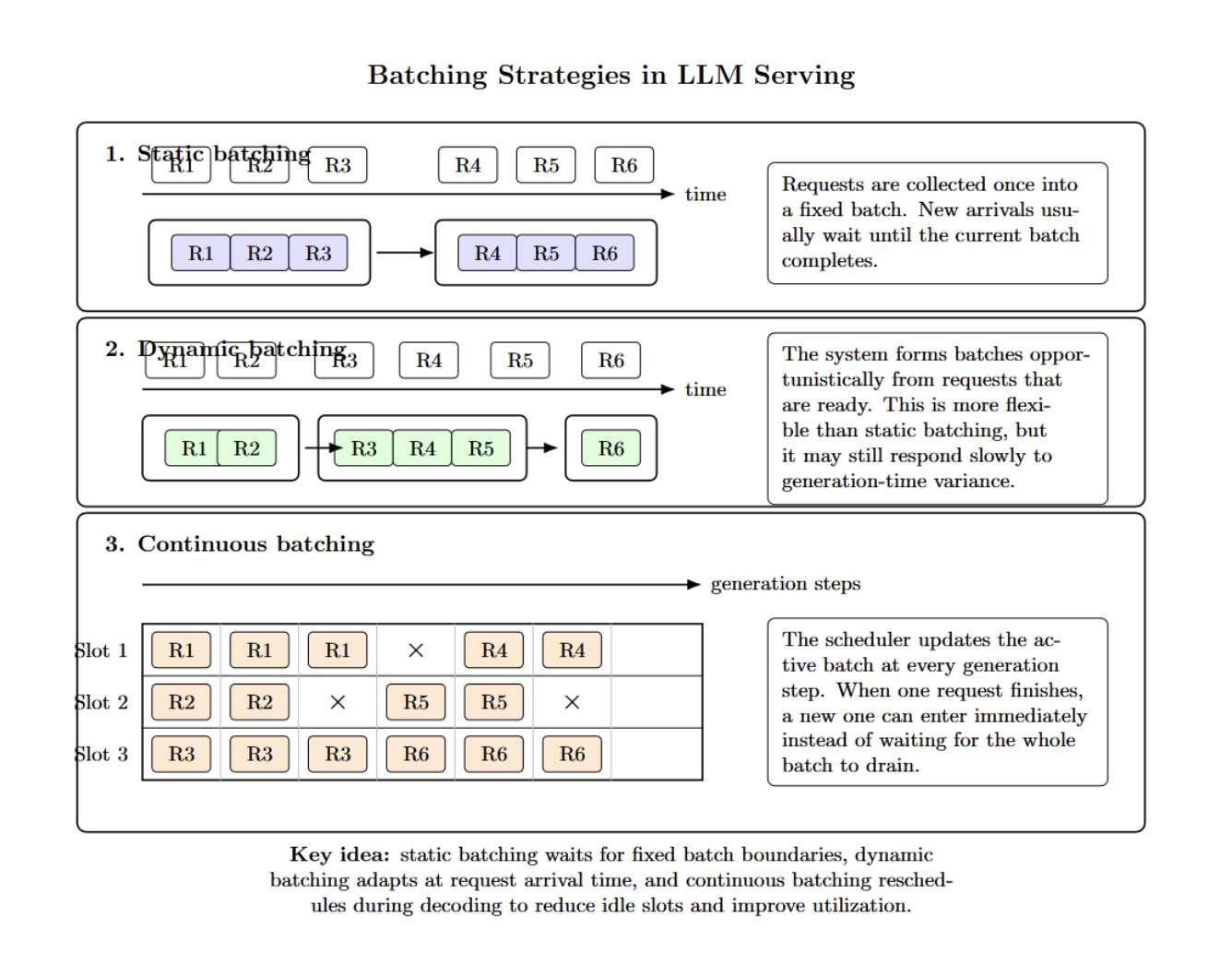
它并非预先组批,而是在每个生成步骤中持续重新调度工作。一旦有请求完成,新的请求会立即填补空缺,无需等待批次排空。系统在每一步生成时都会动态重组批次,以确保 GPU 利用率 始终维持高位。
Hidden Bottleneck #5 — KV Cache Waste and Reuse
KV-cache 是影响服务性能的关键要素之一。它存储了之前 Tok