

By Adrien Payong and Shaoni Mukherjee

Many teams encounter the same frustration when scaling large language model workloads: they buy faster GPUs, roll out a larger inference cluster, and still miss their latency or throughput goals. The reason is straightforward: LLM inference isn’t bound by a single component. Performance hinges on the whole serving stack, from tokenization and prompt preprocessing all the way to KV-cache management, GPU scheduling, and token streaming. In truth, slow inference is frequently a system’s problem.
Modern serving stacks, like vLLM, Hugging Face Text Generation Inference, and TensorRT-LLM, are engineered with this in mind. They emphasize capabilities like continuous/in-flight batching, optimized KV-cache utilization, paged attention, chunked prefill, and scheduling tactics that maximize accelerator usage without sacrificing user-visible latency. This emphasis is key because LLM inference actually exhibits two distinct performance regimes: prefill, which is generally compute-heavy, and decode, which is often limited by memory bandwidth and KV-cache movement, instead of throughput.
This post explores some of the frequently missed bottlenecks that can restrict LLM inference speed in production and offers advice on how to tackle them.
Key Takeaways
- LLM inference is a systems issue, not solely a GPU issue: Performance relies on the full pipeline—from tokenization to KV-cache and scheduling—not just one part.
- Prefill and decode operate fundamentally differently: Prefill is compute-intensive, while decode is frequently memory-bandwidth constrained, needing distinct optimization approaches.
- GPU utilization does not equal efficiency: A system can look active while yielding poor throughput due to memory limits or ineffective scheduling.
- Batching approach and scale directly shape user experience: Bigger batches boost throughput but can harm latency, particularly TTFT and inter-token latency.
- Modern serving frameworks beat traditional designs: Continuous batching, prefix caching, and tuned KV-cache handling greatly enhance real-world performance.
What Actually Happens During an LLM Inference Request
Let’s examine what truly occurs during an LLM inference request. From the outside, each request seems simple. A user sends text and gets tokens back. Internally, the serving pipeline is more complex:
request → tokenization → prefill → KV-cache creation or reuse → decode → GPU scheduling → streamed output
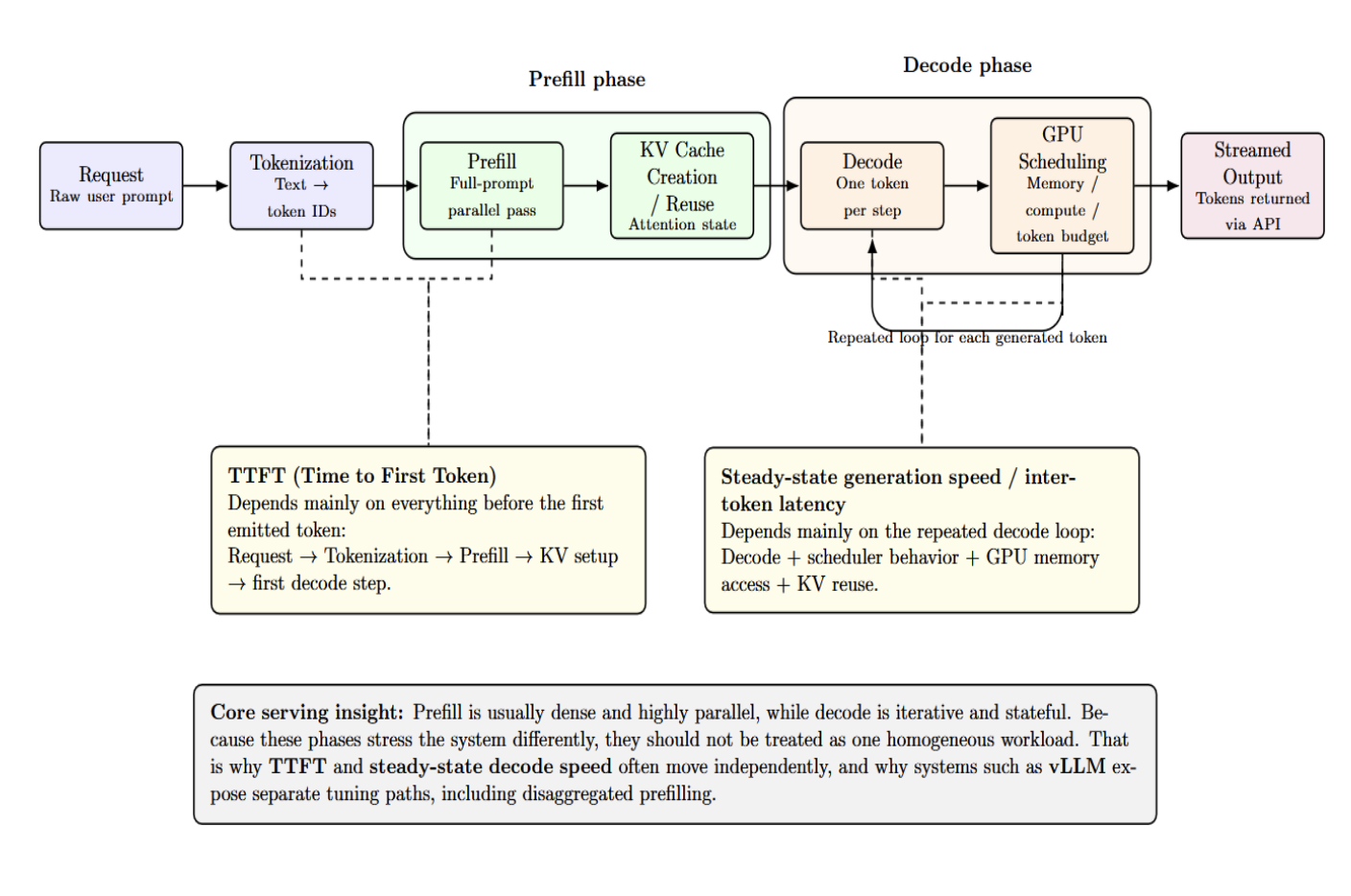
The request must first be tokenized, meaning raw text is turned into IDs matching tokens. Prefill then batch-processes the whole prompt at once, in parallel, and sets up the KV cache. Decode then loops, generating one token at a time and reusing that KV state. The system scheduler then decides how these tasks share GPU, memory, and token resources.
Once decoded, tokens are streamed to users via the API layer. Prefill and decode timing can (and often do) vary because of this. This is why TTFT and steady-state generation speed often move separately: the former relies heavily on everything before the first token, while the latter speed depends on the repeated decode loop.
This split between prefill and decode is a core concept behind LLM serving. Prefill can usually be dense and highly parallel. Decode is inherently iterative and stateful. Systems treating these phases as one uniform workload leave performance gains on the table. This is why vLLM’s workflow actively encourages separate tuning. TTFT is optimized apart from inter-token latency in our dashboard. Its disaggregated prefilling feature exists precisely because those goals often need different optimization tactics.
Hidden Bottleneck #1 — GPU Underutilization
One of the most deceptive metrics in LLM operations is “GPU presence” without real GPU efficiency. A “busy” cluster can still have terrible request throughput. Why?
Because real-world traffic is mixed. Some prompts are brief. Some are lengthy. Some outputs end after twenty tokens. Some take hundreds. Static request-level batching struggles here since the entire batch is often paced by the slowest sequence. When a request ends early, its slot stays idle until the whole batch finishes.
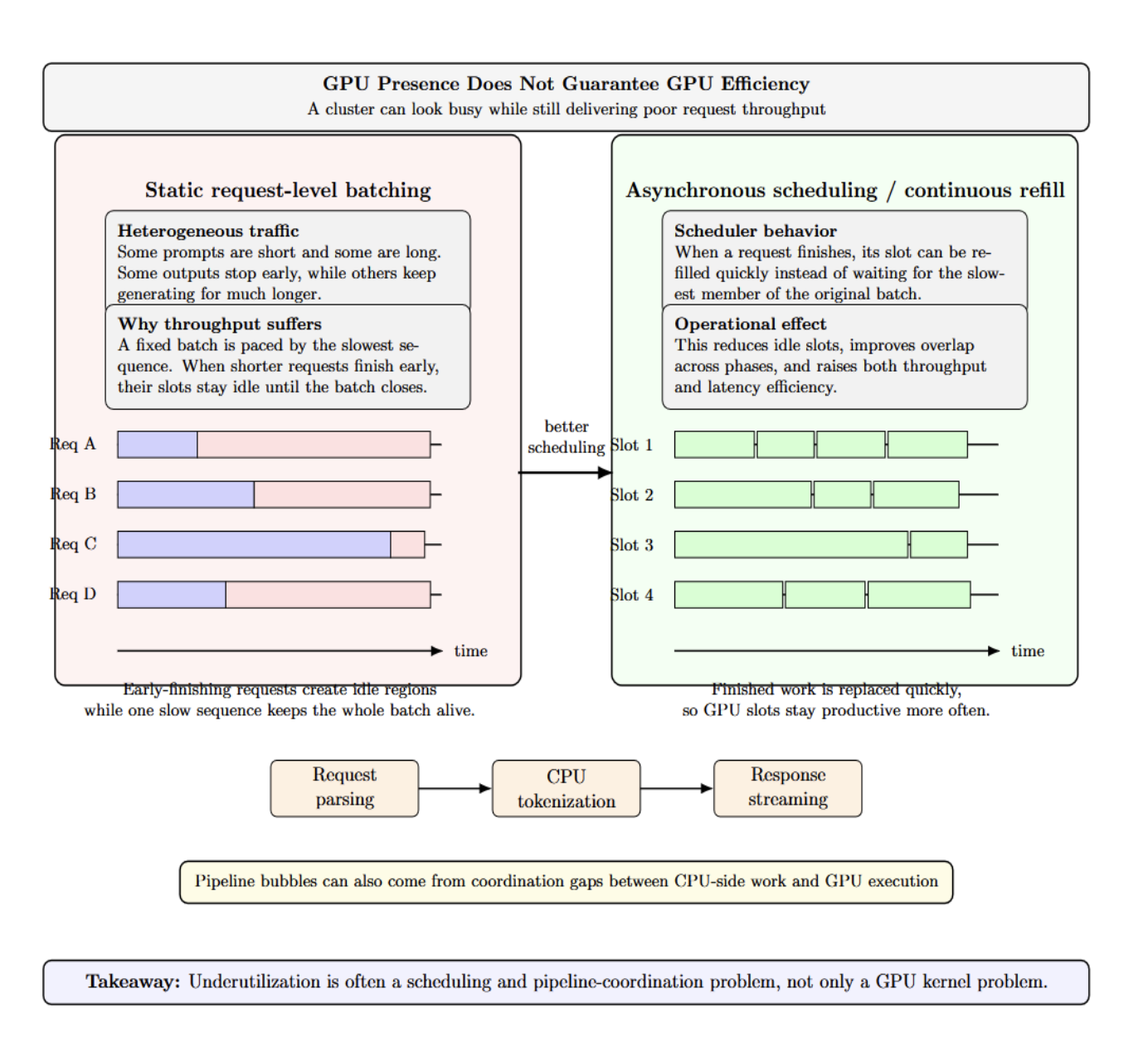
Idle time also occurs between phases. CPU-side preprocessing, tokenization, request parsing, and response streaming create gaps where accelerators wait. vLLM’s serve documentation intentionally surfaces asynchronous scheduling to reduce gaps and improve latency and throughput. Remember: underutilization isn’t always a kernel issue. Sometimes it’s a pipeline coordination issue.
Buying a bigger GPU won’t fix poor scheduling. If your requests are mismatched, if your batches are too stiff, or if the host pipeline can’t feed it, the more powerful accelerator will just sit idle…waiting faster.
Hidden Bottleneck #2 — Memory Bandwidth, Not Raw Compute
There’s a common assumption that inference is a FLOPS problem. The reality is “decode” often becomes memory-bound before compute-bound. Running a model is frequently memory-bandwidth bound. Decode workers are memory-bandwidth bound since they issue tokens singly while repeatedly reading model state and KV data.
This clarifies why systems can show high memory allocation yet low arithmetic usage. GPUs may spend more time shifting weights and KV-cache than doing heavy tensor math during decoding. It’s also why high-bandwidth memory is crucial for serving large models. The bottleneck is often the speed of feeding the next token step, not the peak matrix multiplication rate on a spec sheet.
The implication is “GPU utilization” and “GPU efficiency” aren’t synonymous. A deployment can look loaded yet deliver poor tokens per second because memory traffic is the main limit.
Hidden Bottleneck #3 — Latency vs Throughput Tradeoffs
Every serving team eventually faces the same lure: let’s hike batch size for more throughput. You can do that! But it might hurt user experience. Larger batches typically mean better hardware usage, but they often raise time-to-first-token, tail latency, or inter-token latency if prefills crowd out active decodes. Cutting the batched-token budget often aids inter-token latency, while raising it often helps TTFT and throughput.
This tradeoff means a serving system shouldn’t be optimized by a lone metric. TTFT matters for chat responsiveness. Inter-token latency matters for streaming smoothness. Throughput matters for concurrency and efficiency. vLLM exposes TTFT, TPOT, ITL, end-to-end latency, percentiles, and goodput via our benchmarking and monitoring docs since no single number fully captures inference quality.
The sweet spot hinges on your workload. Interactive chat, batch summarization, agent pipelines, and offline report generation don’t share the same latency envelope. Tuning without those goals is a shot in the dark.
Hidden Bottleneck #4 — Batching Strategy
Not all batching strategies are equal. Static batching groups requests once, then processes them. Dynamic batching is more opportunistic forming batches. Yet it might not react swiftly enough to generation-time variance. Continuous batching differs.
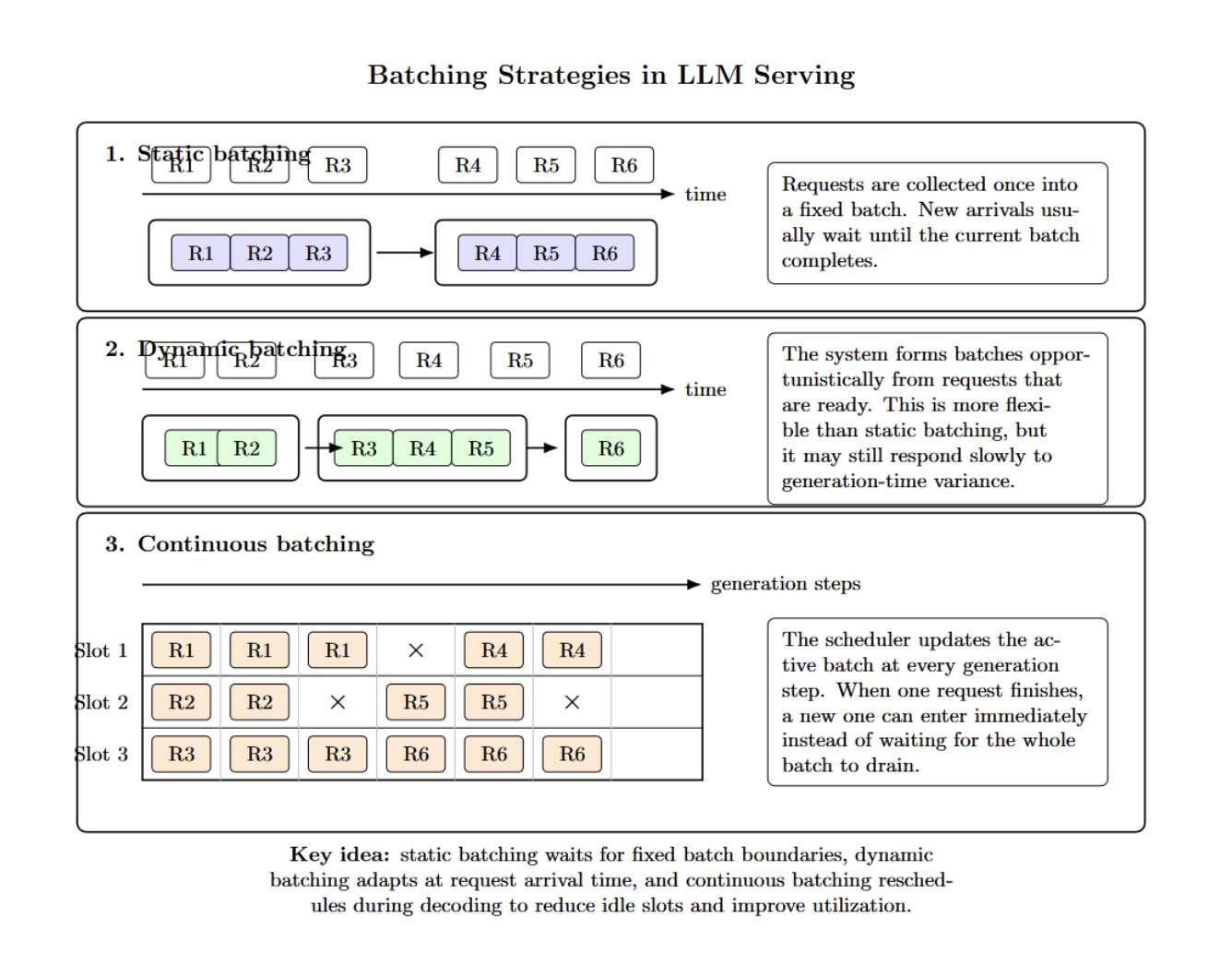
Instead of batching upfront, it constantly reschedules work during each generation step. As requests finish, new ones enter instantly rather than waiting for the batch to clear. The system dynamically reschedules the batch at every step to keep GPU utilization high.
Hidden Bottleneck #5 — KV Cache Waste and Reuse
KV cache is a major factor shaping serving performance. It holds attention keys and values from past toke