AI Pricing Index
How Much Does AI Actually Cost?
Real-time pricing data covering 20+ AI models and tools — refreshed monthly. No signup needed.
Last updated: 2026-05 · Source: OpenRouter
Key Findings 2026-05
- Frontier AI costs $21.13 per million tokens — approximately $0.02 for every 750-word blog post created by GPT-4o or Claude Sonnet. For the majority of small enterprises handling under 10,000 tasks monthly, AI API expenses stay below $50/month.
- Budget models deliver 80-90% of frontier quality at 28x lower cost. The Budget Index sits at $0.76/1M tokens — solutions like Gemini Flash, DeepSeek V3, and Llama 4 manage email drafting, customer replies, and document processing at near-zero marginal expense.
- The price gap between providers is widening. OpenAI's o-series reasoning models can cost up to $262/1M tokens, whereas open-source alternatives from Meta and DeepSeek provide robust results under $1/1M tokens. The "right" model depends entirely on the specific task.
- Most small businesses are overpaying. Consumer subscriptions ($20-200/month) come with usage caps and features most users don't need. API access to the same models typically costs 5-20x less for common small business workloads.
Data sourced from OpenRouter public API. Refreshed monthly. Cite as: AIscending AI Pricing Index, 2026-05. Questions? [email protected]
What Do These Numbers Mean?
The AI CPI follows the average expense of using top-tier AI models (GPT-4o, Claude Sonnet, Gemini Pro, etc.) per million tokens — roughly 750,000 words of input/output combined. If you are building with AI APIs, this serves as your primary benchmark.
The Budget Index follows the same metric for cost-efficient models (Gemini Flash, DeepSeek, Llama, Mistral Small). These deliver 80-90% of frontier quality at a fraction of the price — and represent what most small businesses should actually utilize.
How to Read This Data
Blended Price represents what you would actually pay per million tokens using a typical mix of 75% input and 25% output. Consider it the "real-world cost" of utilizing the model. Input tokens (what you send) are almost always cheaper than output tokens (what the model writes back), so the blend provides a single number to compare apples to apples.
Per 1M Tokens — one million tokens is roughly 750,000 words, about 10 novels. That sounds like a lot, but most small business tasks use only 1,000 to 5,000 tokens per request. A quick customer email might use 500 tokens. Summarizing a 10-page contract might use 8,000. The per-million pricing is just how providers quote rates — divide by 1,000 to get the cost of a single typical request.
Context Length indicates how much text the model can "see" at once. A model with 128K context can process about 96,000 words in a single request — enough for a full book. Longer context means you can feed it bigger documents without splitting them up. Most everyday tasks require less than 8K tokens of context.
AI CPI is our composite index tracking how frontier AI pricing changes month to month — like the Consumer Price Index, but for AI. When the AI CPI drops, it means the same quality of AI output is getting cheaper. We track this so you can time your AI adoption to real market conditions, not hype cycles.
Current AI Model Pricing
Blended price per 1M tokens (75% input, 25% output). Lower is cheaper.
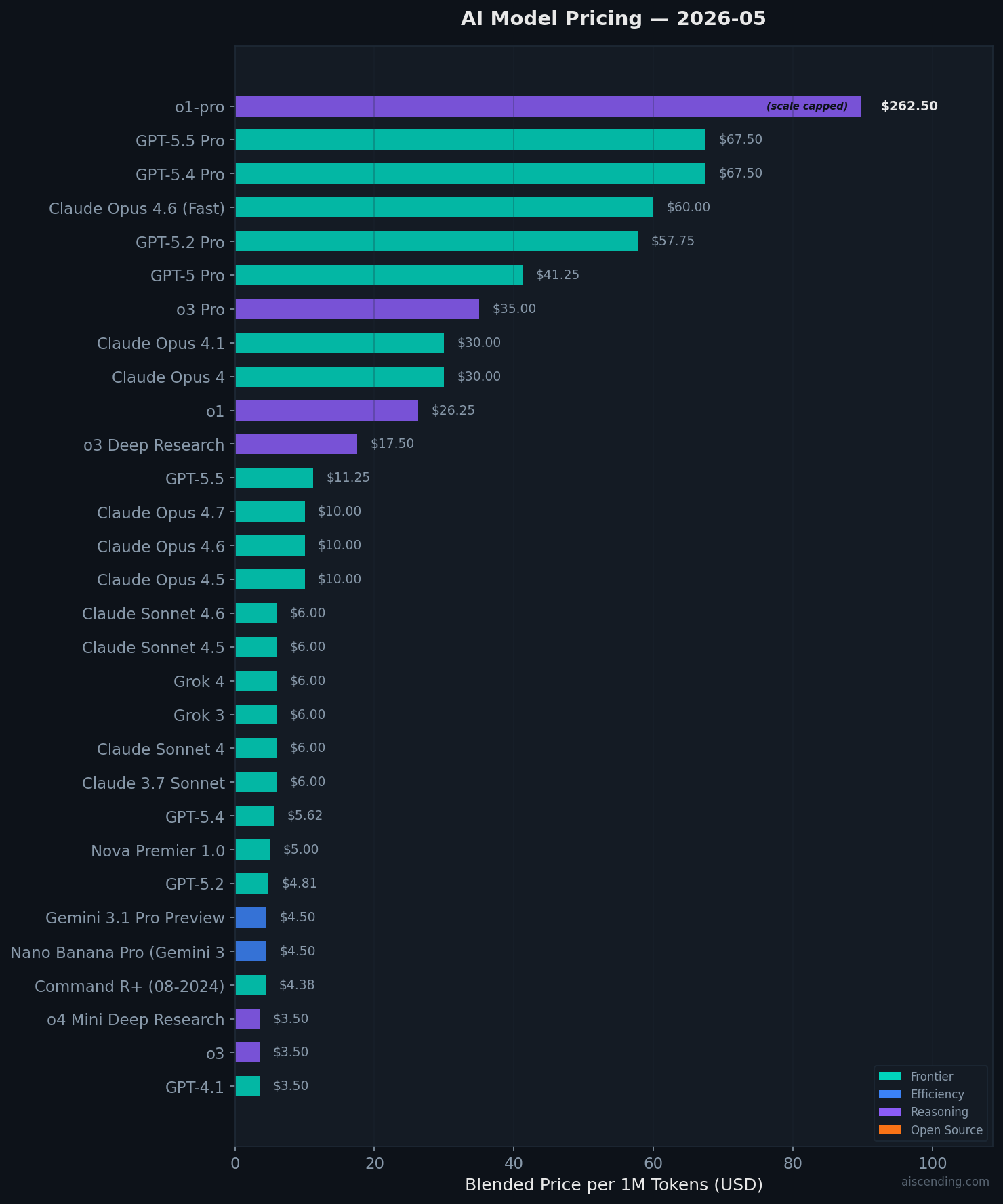
API Pricing — Per 1M Tokens
What developers and automation builders pay. All prices in USD via OpenRouter.
Tip: click any column header to sort.
| Model | Provider | Category | Input / 1M | Output / 1M | Blended / 1M | Context |
|---|---|---|---|---|---|---|
| Mistral Small 3 | Mistral | Efficiency | $0.05 | $0.08 | $0.06 | 32,768 |
| Nova Micro 1.0 | Amazon | Efficiency | $0.04 | $0.14 | $0.06 | 128,000 |
| Command R7B (12-2024) | Cohere | Efficiency | $0.04 | $0.15 | $0.07 | 128,000 |
| Nova Lite 1.0 | Amazon | Efficiency | $0.06 | $0.24 | $0.11 | 300,000 |
| Mistral Small 3.2 24B | Mistral | Efficiency | $0.08 | $0.20 | $0.11 | 128,000 |
| Gemini 2.0 Flash Lite | Efficiency | $0.08 | $0.30 | $0.13 | 1,048,576 | |
| Llama 4 Scout | Meta | Open source | $0.08 | $0.30 | $0.14 | 327,680 |
| GPT-5 Nano | OpenAI | Efficiency | $0.05 | $0.40 | $0.14 | 400,000 |
| Llama 3.3 70B Instruct | Meta | Open source | $0.10 | $0.32 | $0.16 | 131,072 |
| DeepSeek V4 Flash | DeepSeek | Open source | $0.14 | $0.28 | $0.18 | 1,048,576 |
| Gemini 2.5 Flash Lite | Efficiency | $0.10 | $0.40 | $0.18 | 1,048,576 | |
| GPT-4.1 Nano | OpenAI | Efficiency | $0.10 | $0.40 | $0.18 | 1,047,576 |
| Gemini 2.0 Flash | Efficiency | $0.10 | $0.40 | $0.18 | 1,000,000 | |
| Mistral Small 4 | Mistral | Efficiency | $0.15 | $0.60 | $0.26 | 262,144 |
| Llama 4 Maverick | Meta | Open source | $0.15 | $0.60 | $0.26 | 1,048,576 |
| Command R (08-2024) | Cohere | Efficiency | $0.15 | $0.60 | $0.26 | 128,000 |
| Grok 4.1 Fast | xAI | Efficiency | $0.20 | $0.50 | $0.28 | 2,000,000 |
| Grok 4 Fast | xAI | Efficiency | $0.20 | $0.50 | $0.28 | 2,000,000 |
| DeepSeek V3.2 | DeepSeek | Open source | $0.25 | $0.38 | $0.28 | 131,072 |
| R1 Distill Qwen 32B | DeepSeek | Reasoning | $0.29 | $0.29 | $0.29 | 32,768 |
| DeepSeek V3.1 | DeepSeek | Open source | $0.15 | $0.75 | $0.30 | 32,768 |
| DeepSeek V3.2 Exp | DeepSeek | Open source | $0.27 | $0.41 | $0.31 | 163,840 |
| DeepSeek V3 0324 | DeepSeek | Open source | $0.20 | $0.77 | $0.34 | 163,840 |
| Grok 3 Mini | xAI | Efficiency | $0.30 | $0.50 | $0.35 | 131,072 |
| DeepSeek V3.1 Terminus | DeepSeek | Open source | $0.21 | $0.79 | $0.36 | 163,840 |
| Mistral Small 3.1 24B | Mistral | Efficiency | $0.35 | $0.56 | $0.40 | 128,000 |
| GPT-5.4 Nano | OpenAI | Efficiency | $0.20 | $1.25 | $0.46 | 400,000 |
| Grok Code Fast 1 | xAI | Efficiency | $0.20 | $1.50 | $0.53 | 256,000 |
| DeepSeek V4 Pro | DeepSeek | Open source | $0.44 | $0.87 | $0.54 | 1,048,576 |
| DeepSeek V3.2 Speciale | DeepSeek | Open source | $0.40 | $1.20 | $0.60 | 163,840 |
| GPT-5 Mini | OpenAI | Efficiency | $0.25 | $2.00 | $0.69 | 400,000 |
| GPT-4.1 Mini | OpenAI | Efficiency | $0.40 | $1.60 | $0.70 | 1,047,576 |
| R1 Distill Llama 70B | DeepSeek | Reasoning | $0.70 | $0.80 | $0.73 | 131,072 |
| Mistral Medium 3.1 | Mistral | Efficiency | $0.40 | $2.00 | $0.80 | 131,072 |
| Mistral Medium 3 | Mistral | Efficiency | $0.40 | $2.00 | $0.80 | 131,072 |
| Nova 2 Lite | Amazon | Efficiency | $0.30 | $2.50 | $0.85 | 1,000,000 |
| Nano Banana (Gemini 2.5 Flash Image) | Efficiency | $0.30 | $2.50 | $0.85 | 32,768 | |
| Gemini 2.5 Flash | Efficiency | $0.30 | $2.50 | $0.85 | 1,048,576 | |
| Nano Banana 2 (Gemini 3.1 Flash Image Preview) | Efficiency | $0.50 | $3.00 | $1.13 | 65,536 | |
| Gemini 3 Flash Preview | Efficiency | $0.50 | $3.00 | $1.13 | 1,048,576 | |
| R1 | DeepSeek | Reasoning | $0.70 | $2.50 | $1.15 | 64,000 |
| Nova Pro 1.0 | Amazon | Efficiency | $0.80 | $3.20 | $1.40 | 300,000 |
| Grok 4.3 | xAI | Frontier | $1.25 | $2.50 | $1.56 | 1,000,000 |
| Claude 3.5 Haiku | Anthropic | Efficiency | $0.80 | $4.00 | $1.60 | 200,000 |
| GPT-5.4 Mini | OpenAI | Efficiency | $0.75 | $4.50 | $1.69 | 400,000 |
| o4 Mini High | OpenAI | Reasoning | $1.10 | $4.40 | $1.93 | 200,000 |
| o4 Mini | OpenAI | Reasoning | $1.10 | $4.40 | $1.93 | 200,000 |
| o3 Mini High | OpenAI | Reasoning | $1.10 | $4.40 | $1.93 | 200,000 |
| o3 Mini | OpenAI | Reasoning | $1.10 | $4.40 | $1.93 | 200,000 |
| Claude Haiku 4.5 | Anthropic | Efficiency | $1.00 | $5.00 | $2.00 | 200,000 |
| Mistral Large | Mistral | Frontier | $2.00 |
来源:查看原文