AI 定价指数:人工智能的真实成本解析
实时追踪 20+ 款主流 AI 模型与工具的价格数据 — 每月更新,无需注册即可查看。
最近更新:2026年5月 · 数据来源:OpenRouter
预算指数 (高性价比平均)
$0.76
每百万 Token 成本
核心数据洞察 (2026-05)
- 前沿 AI 模型均价为 $21.13 / 百万 Token — 这意味着使用 GPT-4o 或 Claude Sonnet 生成一篇 750 字的博客文章,成本大约是 $0.02。对于大多数月处理任务量低于 10,000 次的小型企业而言,每月的 AI API 费用通常低于 $50。
- 预算模型能以低 28 倍的成本提供达到前沿模型 80%-90% 的质量。 目前的预算指数为 $0.76/百万 Token — 像 Gemini Flash、DeepSeek V3 和 Llama 4 这样的模型,能够以近乎零边际成本处理邮件起草、客户回复以及文档处理工作。
- 不同供应商之间的价差正在扩大。 OpenAI 的 o-series 推理模型成本高达 $262/百万 Token,而 Meta 和 DeepSeek 的开源替代方案在 $1/百万 Token 以下即可提供强大的性能。选择“对”的模型完全取决于具体的任务类型。
- 大多数小型企业都在支付过高的费用。 消费级订阅($20-200/月)通常包含使用限制和大多数用户不需要的功能。通过 API 访问同样的模型,对于典型的小企业工作负载来说,成本要低 5 到 20 倍。
数据源自 OpenRouter 公共 API。每月更新。引用请注明:AIscending AI Pricing Index, 2026-05。如有疑问,请致函 [email protected]
如何解读这些数据?
混合价格 是指按照 75% 输入和 25% 输出的典型使用比例,您实际每百万 Token 需支付的费用。您可以将其视为使用模型的“真实世界成本”。通常输入 Token(您发送的内容)比输出 Token(模型生成的内容)便宜,因此混合价格提供了一个统一的数字,便于进行同类比较。
每百万 Token — 一百万 Token 大约相当于 75 万个单词,或者约 10 本小说的篇幅。这听起来很多,但大多数小型企业的单次请求仅使用 1,000 到 5,000 个 Token。一封简短的客户邮件可能占用 500 个 Token。总结一份 10 页的合同可能需要 8,000 个 Token。按百万计价只是供应商的报价方式 — 除以 1,000 即可得到单次典型请求的成本。
Frontier (前沿模型)
目前能力最强的模型。准确率最高,功能最全,价格也最高。适用于质量优于预算考量场景,如:复杂分析、法律审查、代码架构设计。
Efficiency (效率模型)
针对成本进行优化。能以几分之一的价格提供前沿模型 80%-90% 的质量。对于大多数小型企业任务 — 如邮件草稿、分类、摘要 — 这是明智的选择。
Reasoning (推理模型)
专精于复杂逻辑、数学和多步骤问题。它们在回答前会进行“思考”,成本更高,但在解决科学分析或金融建模等难题时效果更好。
Open Source (开源模型)
社区构建的模型,任何人都可以托管。由于供应商在价格上竞争,这通常是最便宜的选择。非常适合具备技术能力的团队或对成本敏感的生产环境。
当前 AI 模型定价概览
每百万 Token 的混合价格(基于 75% 输入,25% 输出)。数值越低越便宜。
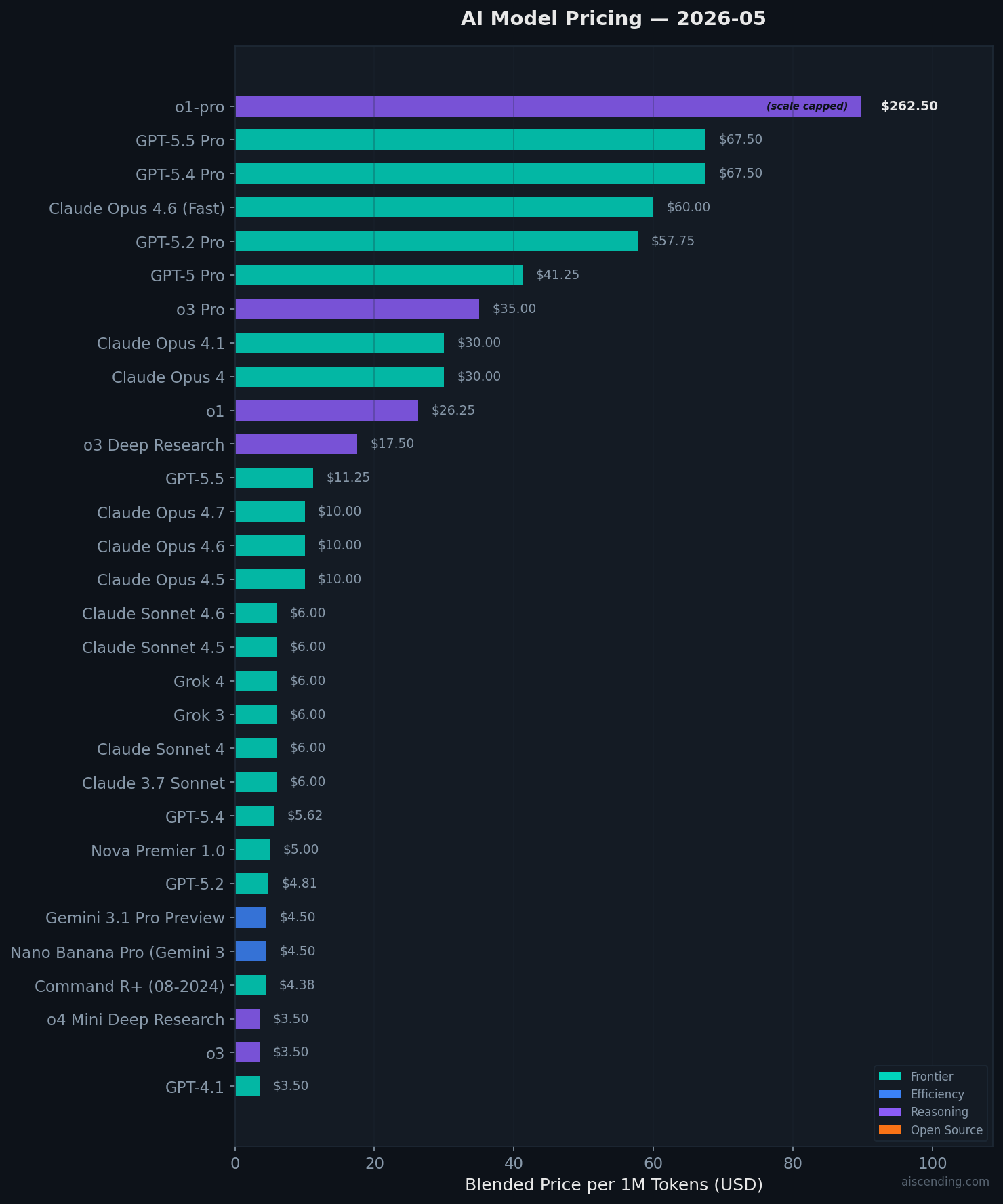
API 价格详情 — 每 1M Token 成本
开发者和自动化构建商支付的费用。所有价格均为美元,通过 OpenRouter 提供。
| 模型名称 | 供应商 | 类别 | 输入价 / 1M | 输出价 / 1M | 混合价 / 1M | 上下文长度 |
|---|---|---|---|---|---|---|
| Mistral Small 3 | Mistral | Efficiency | $0.05 | $0.08 | $0.06 | 32,768 |
| Nova Micro 1.0 | Amazon | Efficiency | $0.04 | $0.14 | $0.06 | 128,000 |
| Command R7B | Cohere | Efficiency | $0.04 | $0.15 | $0.07 | 128,000 |
| Gemini 2.0 Flash Lite | Efficiency | $0.08 | $0.30 | $0.13 | 1,048,576 | |
| Llama 4 Scout | Meta | Open source | $0.08 | $0.30 | $0.14 | 327,680 |
| GPT-5 Nano | OpenAI | Efficiency | $0.05 | $0.40 | $0.14 | 400,000 |
| Llama 3.3 70B | Meta | Open source | $0.10 | $0.32 | $0.16 | 131,072 |
| Gemini 2.5 Flash Lite | Efficiency | $0.10 | $0.40 | $0.18 | 1,048,576 | |
| GPT-4.1 Nano | OpenAI | Efficiency | $0.10 | $0.40 | $0.18 | 1,047,576 |
| Mistral Small 4 | Mistral | Efficiency | $0.15 | $0.60 | $0.26 | 262,144 |
| Llama 4 Maverick | Meta | Open source | $0.15 | $0.60 | $0.26 | 1,048,576 |
| Command R | Cohere | Efficiency | $0.15 | $0.60 | $0.26 | 128,000 |
| Grok 4.1 Fast | xAI | Efficiency | $0.20 | $0.50 | $0.28 | 2,000,000 |
| R1 Distill Qwen 32B | DeepSeek | Reasoning | $0.29 | $0.29 | $0.29 | 32,768 |
| DeepSeek V3.1 | DeepSeek | Open source | $0.15 | $0.75 | $0.30 | 32,768 |
| Grok 3 Mini | xAI | Efficiency | $0.30 | $0.50 | $0.35 | 131,072 |
| GPT-5.4 Nano | OpenAI | Efficiency | $0.20 | $1.25 | $0.46 | 400,000 |
| GPT-5 Mini | OpenAI | Efficiency | $0.25 | $2.00 | $0.69 | 400,000 |
| GPT-4.1 Mini | OpenAI | Efficiency | $0.40 | $1.60 | $0.70 | 1,047,576 |
| R1 Distill Llama 70B | DeepSeek | Reasoning | $0.70 | $0.80 | $0.73 | 131,072 |
| Gemini 2.5 Flash | Efficiency | $0.30 | $2.50 | $0.85 | 1,048,576 | |
| Gemini 3 Flash Preview | Efficiency | $0.50 | $3.00 | $1.13 | 1,048,576 | |
| R1 | DeepSeek | Reasoning | $0.70 | $2.50 | $1.15 | 64,000 |
| Nova Pro 1.0 | Amazon | Efficiency | $0.80 | $3.20 | $1.40 | 300,000 |
| Grok 4.3 | xAI | Frontier | $1.25 | $2.50 | $1.56 | 1,000,000 |
| Claude 3.5 Haiku | Anthropic | Efficiency | $0.80 | $4.00 | $1.60 | 200,000 |
| GPT-5.4 Mini | OpenAI | Efficiency | $0.75 | $4.50 | $1.69 | 400,000 |
| o4 Mini High | OpenAI | Reasoning | $1.10 | $4.40 | $1.93 | 200,000 |
| o3 Mini High | OpenAI | Reasoning | $1.10 | $4.40 | $1.93 | 200,000 |
| Claude Haiku 4.5 | Anthropic | Efficiency | $1.00 | $5.00 | $2.00 | 200,000 |
| Mistral Large | Mistral | Frontier | $2.00 | $6.00 | $3.00 | 128,000 |